De plus en plus d’entreprises franchissent le pas en recrutant des Data Scientists. LinkedIn liste ce métier dans le top 15 des métiers émergents ou d’avenir en 2019. Mais la Data Science reste souvent perçue dans ces entreprises comme un sujet d’expérimentation ou de R&D. Elle serait ainsi menée à l’initiative d’un lab d’innovation ou autre cellule d'intrapreneuriat. L'organisation Produit Data doit alors évoluer.
En réalité, lorsqu’on recrute des Data Scientists, c’est tout autant pour faire de l’expérimentation, que pour répondre à une ambition précise : améliorer les Produits et les process digitaux. On parle dès lors de Produits Data. Ce sont des produits dont le coeur de la proposition de valeur est apporté à l’utilisateur grâce au Machine Learning.
Pourquoi parler des Data Scientists dans l’organisation Produit ?
Entre les Product Managers et les Data Scientists, le fossé est encore trop grand. Pourtant le sujet est critique : le Machine Learning est une solution technologique qui permet de résoudre des besoins utilisateurs jusqu’ici délaissés, ou gérés par des règles métiers obsolètes et inefficaces. Celui-ci permet par exemple, d’optimiser la recommandation de Produits sur un site d’e-commerce, de combattre la fraude financière plus efficacement, ou d’optimiser le calcul du prix d’une course de VTC. Les Product Managers eux incarnent leur Produit. Ils sont les plus aptes à définir les problèmes qui devraient être traités en priorité par les Data Scientists.
Sans collaboration entre les Product Managers et les Data Scientists, les Produits sont privés de la valeur ajoutée du Machine Learning. Le risque majeur est d’occulter les problèmes utilisateurs les plus urgents et d’enchainer les proof-of-concepts, qui peinent à aller au-delà de la phase d’expérimentation. Les données elles-mêmes restent en silos en l’absence d’une réelle synergie.
Repenser l'organisation Produit avec les Data Scientists
Repenser l’organisation Produit avec les Data Scientists apparaît dès lors comme une nécessité. Il existe une multitude de modèles organisationnels pour intégrer les Data Scientists à l’organisation Produit. Chacun de ces modèles présente des forces et des faiblesses. Chaque organisation devra par conséquent faire son choix d’intégration, selon son secteur d’activité, sa taille, son modèle organisationnel, le nombre de Data Scientists et Data Engineers, ainsi que la maturité Produit et la maturité Data Science de l’entreprise.
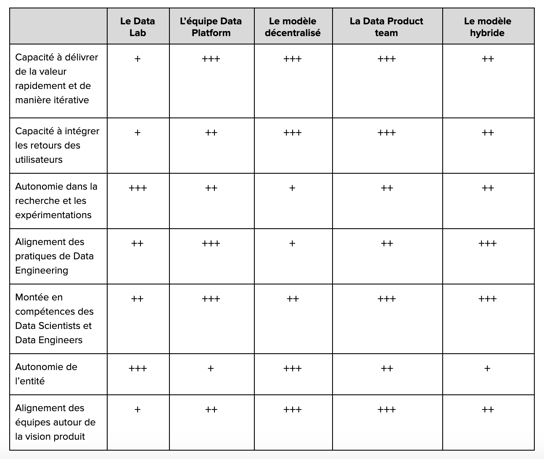
On distingue globalement trois grandes familles de modèles : les modèles centralisés, les modèles décentralisés et les modèles hybrides. Nous avons choisi d'illustrer quatre modèles, qui sont sans surprise, les plus communs aujourd’hui dans les entreprises. Nous les évaluons enfin au regard de plusieurs axes :
- Capacité à délivrer de la valeur rapidement et de manière itérative ;
- Capacité à intégrer les retours des utilisateurs ;
- Autonomie dans la recherche et les expérimentations ;
- Alignement des pratiques de Data Engineering ;
- Montée en compétences des Data Scientists et Data Engineers ;
- Alignement des équipes autour de la vision produit ;
- Autonomie de l’entité.
Le Data Lab
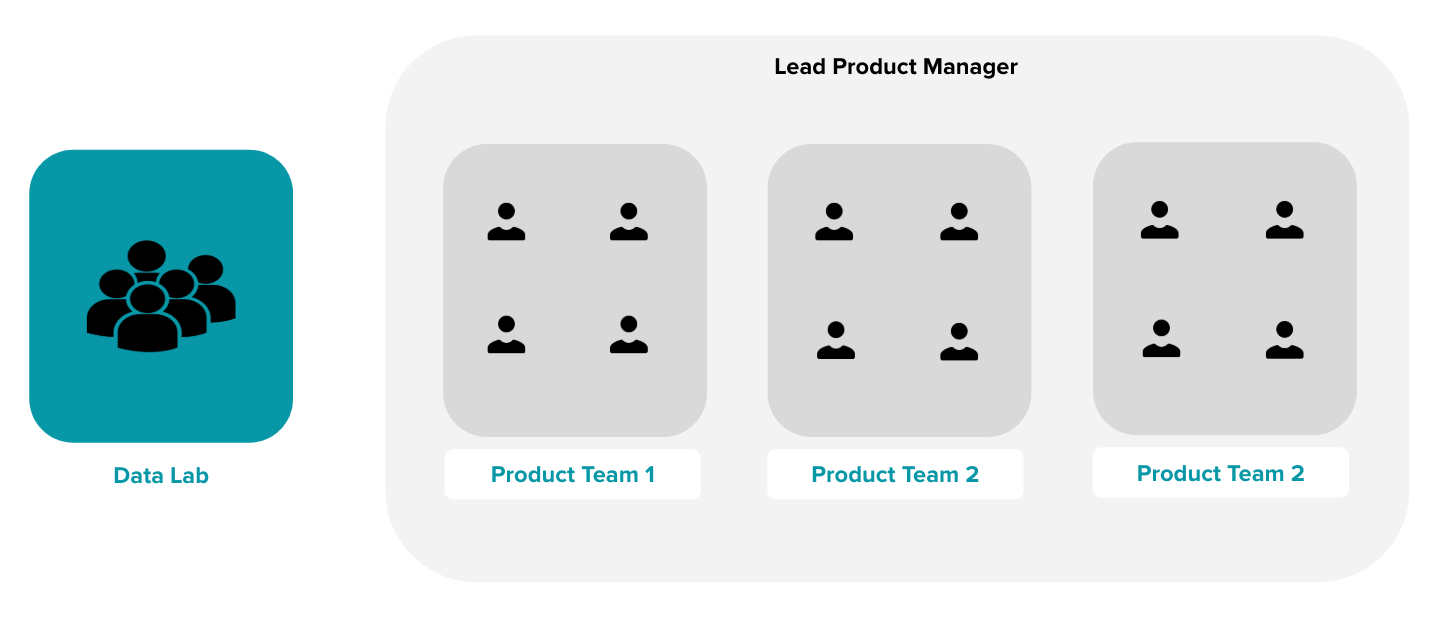
Le Data Lab est une entité autonome au sein de l’entreprise. Souvent, celle-ci regroupe des Data Scientists, et plus rarement des Data Engineers. Le Data Lab dépend souvent du Chief Data Officer (ou CDO), et les Data Scientists et Data Engineers baignent dans un environnement de recherche. Les attentes de ces structures sont multiples. L’équipe est responsable de faire des recherches, mener des expériences autour de l’état de l’art en Data Science et de réaliser des prototypes.
Ce modèle est privilégié par un certain nombre d’entreprises pour plusieurs raisons :
- L’autonomie du lab, qui lui permettra de creuser ses expérimentations sans se soucier des process contraignants.
- La vitesse d'exécution, particulièrement valable lorsque les dépendances avec les équipes Produit sont faibles.
Limites
Mais très rapidement, ce modèle d’intégration montre quelques limites :
- Le Data lab est rarement capable d’assurer la partie “delivery” ou le mode “run” dans la conception du Produit. Cela engendre plusieurs problèmes autour de l'ownership des sujets en cours. Qui reprend le sujet une fois l’expérimentation terminée et la valeur prouvée ?
- La faible connaissance du métier et des besoins utilisateurs, incarnés par les équipes Produit. Cela mène très souvent à des proof-of-concepts décorrélés des besoins et priorités du produit.
L’équipe Data plateform
L’équipe Data Plateform est une variante très intéressante du datalab, de plus en plus adoptée par les entreprises. Il s’agit d’un mode organisationnel centralisé, où l’équipe Data Science s’inspire des bonnes pratiques des équipes Produit et agit en tant que telle. L’équipe recueille les besoins auprès de l’ensemble des autres équipes Produit. Elle livre souvent une plateforme Data, un point d’entrée vers un Data Lake et/ou des API vers des services de Machine Learning.
Dans ce mode organisationnel, il est important que l’équipe Produit Data soit également constituée de Data Scientists et de Data Engineers, et pourvue d’un Data PM. Ce dernier qui se charge de collecter les besoins des autres équipes Produit, de les prioriser et transmettre l’expertise métier aux Data Scientists.
Ce mode organisationnel permet de pallier à quelques problèmes auxquels se confrontent habituellement les Data Lab. Il assure une meilleure priorisation, une grande proximité entre les Data Scientists et les Data Engineers. Il réduit l'isolement de l'équipe et le risque que les initiatives soient cantonnées à la phase du POC.
Limites
En revanche, il peut engendrer de nouvelles complications :
- Sous cette organisation, la dépendance avec les autres équipes Produit est plus grande.
- L’équipe reste cantonnée dans une logique de client/fournisseur.
- Il y a un risque que l'équipe agisse comme un goulot d’étranglement, et se disperse trop entre les différents sujets en cours, souvent en lien avec différents Produits.
- L’équipe n’a presque pas la main sur l’activation de son produit Data.
Le modèle décentralisé
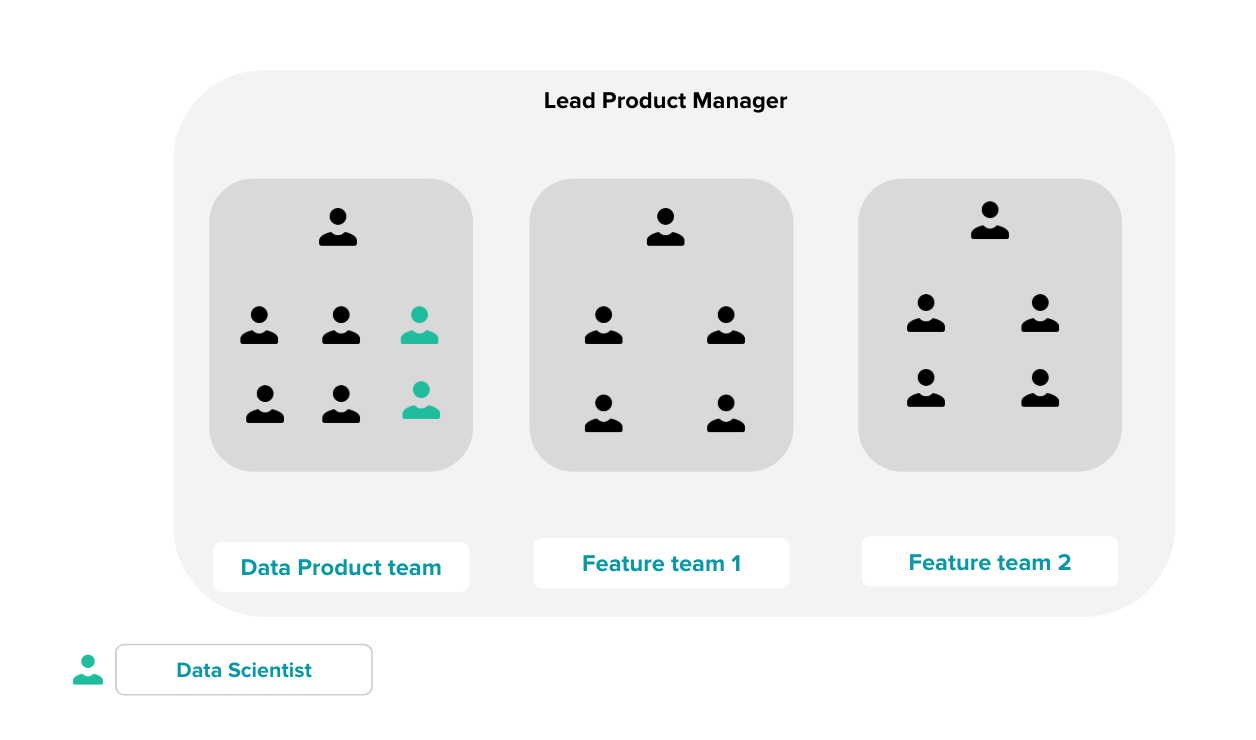
Ici, on désigne un modèle sous lequel chaque équipe se charge de la conception d’un Produit ou d’une feature Data de bout-en-bout. L’équipe est une feature team au même titre que les autres équipes Produit. Elle comporte habituellement des Data Scientists, des Data Engineers, des développeurs Back et Front. Elle est autonome et multidisciplinaire. Ce modèle organisationnel, extrêmement décentralisé, vise à maximiser l’autonomie et l’indépendance des squads Produit. Cela leur permet d’apporter de la valeur rapidement et de façon itérative. Très vite, l’entreprise va voir ces entités se multiplier, jusqu’à peut-être atteindre l’inclusion systématique de Data Scientist dans chaque feature team.
Chaque équipe dispose d’un ou de plusieurs Data Scientists et/ou Data Engineers. Souvent l’équipe recrute ce Data Scientist lorsqu’elle souhaite créer une nouvelle feature Machine Learning (ML pour les intimes). En adoptant ce modèle, l’équipe est en charge de la conception de son Produit de bout-en-bout. De la conception du modèle à son activation, en passant par le nettoyage et la structuration des données. Par conséquent, elle est beaucoup moins confrontée aux problèmes d’ownership, constatés dans des modèles organisationnels plus centralisés.
Limites
Mais une équipe cross-fonctionnelle est souvent susceptible de rencontrer certaines difficultés :
- Il est très difficile sous ce modèle d’assurer une cohérence dans les pratiques Data, d’établir des standards technologiques ou d’instaurer du peer reviewing entre Data Scientists.
- L’équipe est confrontée à la persistance des données en silos, à la redondance des workflows ou data pipeline, à défaut de disposer d’une vraie infrastructure de données (data lake ou data warehouse) centrale.
- Le côté “expérimental” du travail mené par le Data Scientist peut sembler incompatible avec le mode “run” du reste de l’équipe.
- Faire coïncider les rythmes des Data Scientists et de l’équipe de développement demande une forte collaboration entre les membres. L’équilibre peut-être difficile à trouver.
- Les besoins en Machine Learning pour une squad donnée peuvent varier grandement d’un sprint à un autre. Le Data Scientist peut rapidement manquer de sujets à traiter si les priorités du Produit ne vont pas dans ce sens.
- La concentration des profils Data dans une seule équipe ralentit la montée en compétence de l’ensemble de l’organisation sur le sujet.
La Data Product Team
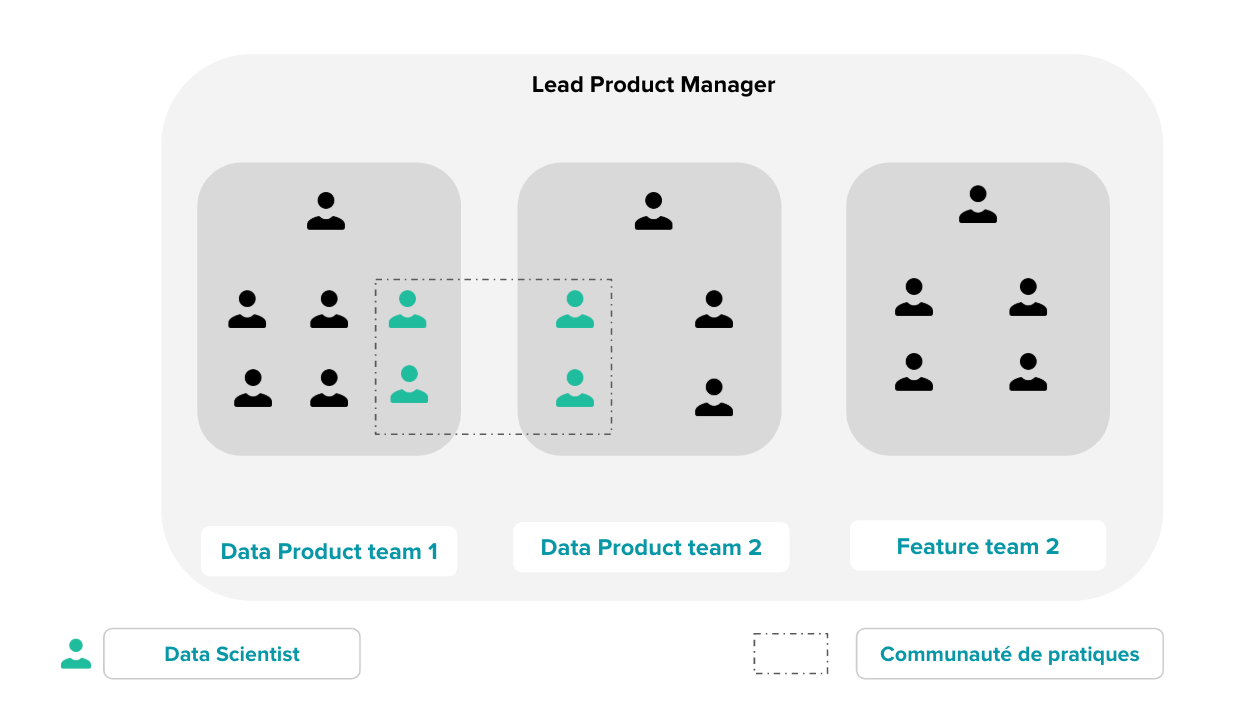
On introduit ici une nouvelle variante. Son objectif est de mitiger efficacement certains risques associés au modèle décentralisé. Particulièrement lorsque le Machine Learning connaît l’essor escompté, et que les équipes Produits Data deviennent de plus en nombreuses.
Dans ce cas de figure, on recommande de créer une communauté de pratiques (ou Tribe) autour du Machine Learning et du Data Engineering. Les Data Scientists y allouent une proportion de leur temps d’activité, ne dépassant pas 20%. Cela leur permet :
- D’allouer du temps à la recherche et à l’expérimentation,
- De standardiser leur travail et d’aboutir à des bonnes pratiques,
- D’échanger entre Data Scientists et de pratiquer le peer-reviewing.
Le modèle hybride
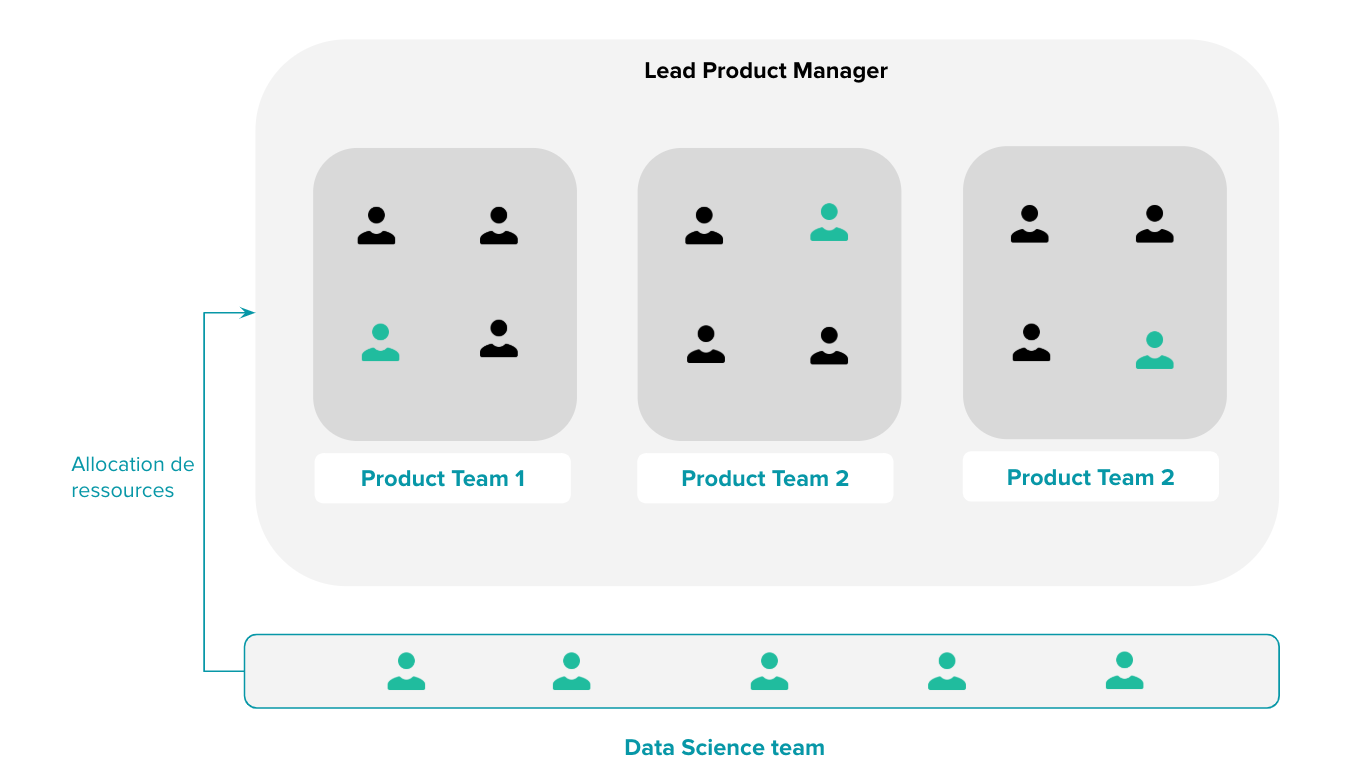
Le modèle hybride, comme son nom l’indique, est une combinaison des approches introduites plus haut. Dans ce modèle d’organisation, les Data Scientists font partie des équipes Produit mais aussi d’une entité centrale de Data Science. Les Data Scientists se placent successivement dans les différentes équipes Produit selon les priorités et la stratégie globale. Cela leur permet de baigner à plus long terme dans l’environnement Produit, de s’imprégner des problèmes des utilisateurs, et de bénéficier de l’expertise métier des Product Managers.
Sous une direction unifiée, les Data Scientists bénéficient également des avantages des modèles organisationnels plus centralisés. Ils ont ainsi la possibilité de collaborer entre pairs et d’instaurer des bonnes pratiques de développement, ou de se focaliser sur des sujets traités au sein de l’entité Data Science (mise en place d’un data lake, nouvelle approche expérimentale…)
La répartition du temps d’activité des Data Scientists entre l’équipe centrale et les différentes équipes Produit, reste à définir. A l’instar des communautés de pratiques, il est souvent de 10 à 20%.
Limites
Mais rien n’est parfait, et le modèle hybride non plus :
- il est nécessaire ici encore d’établir des critères d’allocation de ressources. Cela implique un besoin d’instaurer une forme de priorisation, à l’instar de ce qui est réalisé par les équipes Produit Data Science.
- Ce modèle ne permet pas non plus de sortir de la logique binaire de client/fournisseur, entre d’un côté les Data Scientist et de l'autre côté les équipes Produit.
- Les Data Scientists changent très régulièrement d’équipe. D’une part cela les empêche de s’intégrer efficacement dans la démarche d’amélioration continue des pratiques. D’autre part cela sera difficile pour eux d’acquérir une expertise suffisante sur le périmètre de l’équipe qu’ils intègrent pour être force de proposition.
Take away
Vous l’aurez compris, nous pensons que la Data Science et le Product Management vont de pair pour répondre aux problèmes des utilisateurs et améliorer leurs expériences du digital. Il est très important de souligner que le choix du modèle organisationnel ne se base pas uniquement sur ses critères. Il dépendra avant tout de la maturité Produit et data de l’entreprise.
Cet article s’inscrit dans une série, dédiée à l’intégration de différentes spécialités au sein de votre Organisation Produit :
👉Le Product Growth dans votre organisation Produit
👉Le Product Design dans votre organisation Produit



-3.png)
