Avec ton équipe, vous avez accumulé de précieuses informations sur les utilisateurs au fil de vos recherches. Vos synthèses sont bien fournies mais le plus dur reste à venir : comment analyser ces informations sans perte et en limitant les biais ? Comment partager les enseignements-clés au sein de votre organisation ?
Tu mises peut-être sur des slides exhaustives, très utiles pour présenter les enseignements de la recherche mais qui risquent malheureusement de finir au fond d’un drive… pour n’être que rarement (voire plus du tout) ouvertes ? Plus gênant, cette méthode de restitution ne garantit pas d’identifier les points d’adhérence de ton travail avec les autres études qui sont, ou seront, menées par d’autres designers.
Autre cas de figure : tu fais partie d’une petite équipe, où le partage d’informations est moins structuré et plus informel ? Tu es probablement habitué·e à communiquer directement les enseignements de tes recherches à tes Product Managers… au risque que ce bouche-à-oreille soit synonyme de déperdition de l’information.
À travers les retours d’expériences de Product Designers de Thiga en mission chez LeBonCoin (l’un des sites leaders de petites annonces B2C et B2B2C) et Alma (une solution de paiement en plusieurs fois), nous te proposons différentes façons de structurer et de capitaliser sur la recherche utilisateurs.
Nous parlerons alors de repository de recherche. Mais concrètement, qu’est-ce que c’est ?
Le Nielsen Norman Group définit le repository de recherche comme “une collection partagée d'éléments liés à la recherche en UX qui devrait soutenir les fonctions suivantes au niveau d’une organisation :
- Accroître la sensibilisation à l’UX et la participation au travail de recherche utilisateur des dirigeants, des propriétaires de produits et l'organisation dans son ensemble.
- Soutenir le travail de recherche UX, afin que les professionnels de l'UX puissent être plus productifs lorsqu'ils planifient et suivent la recherche.”
Que tu sois Designer dans une grande organisation Produit ou dans une plus petite structure, l’intérêt est donc multiple : créer un document partagé, consulté par toutes les parties prenantes, et qui permet de capitaliser sur les enseignements des études utilisateurs afin de guider les décisions Produit. Rien que ça ! 😉
Dans cet article, nous verrons quelles étapes initier pour centraliser les apprentissages de la recherche utilisateurs, puis comment structurer ton repository. Ça te parle ? Alors, place à la pratique !
Cadrer son besoin de repository de recherche
Faire un état des lieux de l’existant
Créer un repository de recherche est un travail de longue haleine, requérant de l’expertise en recherche utilisateurs et de la collaboration avec d’autres Designers et Product Managers. Avant de se lancer tête baissée sur le sujet, demandons nous dans quel contexte un tel outil est utile.
1ère question à se poser : jusqu’à présent, combien de recherches ont été conduites dans ton organisation ?
Si très peu de recherches (exploratoires ou orientées) ont été menées, la priorité serait plutôt d’évangéliser ton équipe pour commencer à en lancer. 😉
Pour autant, de la même façon qu’il est utile de penser à sa restitution avant d’animer un test utilisateur ou un atelier, il est intéressant de réfléchir à la création du repository car cela t’aidera à centraliser et prioriser les futurs retours utilisateurs afin de partir sur des bases solides.
À l’inverse, si ton Drive ou ton Notion croule sous les restitutions, c’est une excellente raison de te lancer !
Commence par regrouper les études existantes et à identifier quelles en sont les caractéristiques principales :
- Exploratoire ou orientée ? Quantitative ou qualitative ? Méthode employée ?
- Quand ont-elles été menées ? Par qui ?
- Sur quelle population d’utilisateurs ?
- Qui sont les équipes ou squads à l’origine ou concernées par chaque étude ?
💡 Ces critères te permettront de choisir quelle(s) étude(s) intégrer en premier dans le futur repository pour en tester le format.
2e question : qui conduit les recherches utilisateurs ? Combien de Designers composent l’équipe et combien sont arrivés dans les six derniers mois ?
Si l’équipe design est en pleine croissance et qu’un bon nombre de collaborateurs (au produit, mais aussi au marketing, au commerce, etc.) font, écoutent et/ou lisent des restitutions, bingo ! Le repository n’en sera que plus utile.
C’est le cas chez Alma, qui évolue dans un secteur très compétitif et a donc besoin de se démarquer régulièrement par de l’innovation. Dans ces organisations, la recherche est clé car elle permet d’identifier des opportunités qui pourront ensuite alimenter les roadmaps Produit.
Tu peux lister les parties prenantes, avec leurs différents rôles. À terme, cela t’aidera à définir une gouvernance :
- Qui contribue à récolter et restituer des insights (User Researchers, UX Designers, Product Designers, Chargés d’études marketing…) ?
- Qui s’en sert, et pourquoi (améliorer le produit, proposer de nouvelles offres…) ?
💡 Les retours utilisateurs peuvent provenir de nombreux acteurs : les User Researchers et les Product Designers, mais aussi les collaborateurs du Service Client, les Commerciaux, les Chargés d’études au niveau marketing… Un sujet dont on parlait déjà dans cet article sur la gestion des retours utilisateurs à l’échelle de toute une organisation.
Identifier en amont le rôle de chaque intervenant·e facilite l’évangélisation et la prise en main du futur repository. Comme pour un Design System, un repository de recherche n’a de valeur que lorsqu’il est partagé !
3e question (mais sans doute pas la dernière 😉) : quelle connaissance a ton organisation des utilisateurs de son produit ?
L’un des objectifs d’un repository de recherche est d’améliorer la compréhension des besoins et usages des différents profils d’utilisateurs auxquels s’adressent le produit, afin de guider la prise de décisions sur la base de faits concrets, précis et sourcés.
Deux principaux cas de figure peuvent exister :
- Dans le cas où des profils utilisateurs (segments, personae…) sont déjà conçus, tu peux les associer à des études.
- Dans le cas contraire, tu peux dans un premier temps organiser des ateliers de co-création de proto-personae sur la base des critères de recrutement des études réalisées. À terme, cette classification sera à raffiner.
👉 Pour être sûr·e de ne rien oublier et t’assurer de l’utilité de ta démarche, ces tableaux synthétiques sont tes pense-bête :
🧐 [Take Away] État des lieux avant de monter un repository de recherche
Adopter une démarche MVP
Au même titre qu’un design system, un repository de recherche est un produit à usage interne : mieux vaut commencer petit et itérer régulièrement ! Comme les futurs utilisateurs de ton repository sont tes collègues, tu pourras le co-concevoir avec eux.
Fonder une core team
Des Heads Of et des sponsors convaincus, du temps alloué… Ça y est tu as toutes les clés en main pour commencer à monter un repository. Enfin… presque.
Te lancer seul·e sur ce chemin relève davantage de l’iron man que de la promenade de santé du dimanche. Et malheureusement, sans aucune garantie de réussite malgré les efforts déployés. Comme pour toute initiative, il n’y a pas de secret : l’union fait la force !
Grâce à la liste des parties prenantes définie en amont, identifie les personnes avec lesquelles collaborer. Privilégie autant que possible celles ayant le plus de séniorité en recherche utilisateurs et varie les degrés d’ancienneté au sein de l’entreprise. Inutile d’être trop nombreux au début : les parties prenantes seront à intégrer au fur et à mesure. Si tu as la chance d’en avoir dans ton organisation, un·e User Researcher est cependant une personne-clé à associer dès le début des réflexions.
Le sponsorship des managers ou de spécialistes du sujet est un également élément-clé de réussite de cette initiative, car il lui apportera de la visibilité.
💡 Ton organisation est sur plusieurs marchés (B2C, B2B, B2E…) ? Identifie des experts (User Researcher, UX Designer, Product Designer…) et intègre les régulièrement.
Tu es le·la seul·e Designer ? Prends appui sur un Product Manager ou un Product Owner sensible au Discovery.
Félicitations, l’équipe REPO est née ! 🥳 Une fois le noyau solide de ton équipe consolidé, à vous d’en définir la gouvernance.
Programmez ensemble des points réguliers et planifiez les grandes étapes : analyse de l’existant, choix du périmètre, test du POC, présentation du POC, formation à l’utilisation…
Rendez ces phases visibles sur un kanban : il vous servira de calendrier, d’aide-mémoire et d’outil de communication auprès des décideurs.
Tester le repository sur un (petit) périmètre
Si faire un repository partagé à l’échelle de toute l’organisation est une démarche louable, l’expérimenter à une échelle plus restreinte est moins risqué.
En accord avec les décideurs (CPO, Head Of PM et/ou Design…) et les membres de l’équipe REPO, choisissez une tribe voire une squad sur lequel démarrer le repository. Plusieurs critères peuvent entrer en jeu :
- Le nombre de recherches menées en un trimestre (ou quarter, ou année) et la variété de ses utilisateurs (plus il y en a, plus c’est difficile mais représentatif).
- Les opportunités business et les OKR.
- La séniorité en Discovery de ses membres, et leurs disponibilités.
- L’influence et la dépendance de l’équipe vis-à-vis des autres…
Impossible de se décider ? Tu peux aller jusqu’à noter chacun de ces critères par squad :
| Critères | Note équipe A (de 1 à 5) | Détail sur la note |
| Nombre de recherches | 3 | Entre 5 et 6 études menées par trimestre |
| Influence | 4 | Équipe conduisant des études sur des sujets très transverses |
| ... |
En limitant le périmètre, ton analyse de l’existant et ta phase de test seront moins longues.
Il ne s’agit pas de mettre de côté les autres équipes, mais d’éviter les risques en limitant le temps passé sur la première version du repository qui, spoiler alert, ne sera pas la bonne du premier coup.
Chez LeBonCoin, une première étude via du shadowing a permis de crash-tester le repository monté sur Airtable. Il a ensuite été testé et adopté par d’autres squads. Profite des rituels dédiés aux sujets design pour faire part de l’avancée de l’équipe REPO et ainsi réduire les frustrations.
Choisir le bon outil
Avec l’avènement d’outils de plus en plus collaboratifs, choisir le bon est devenu essentiel… et la marge d’erreur est réduite car il est plus difficile de revenir en arrière.
Le meilleur outil est parfois celui qui est déjà utilisé en interne car les futurs utilisateurs du repository le maîtrisent déjà, et l’organisation a déjà investi dans une licence. Par ailleurs, les services clients, en permanence au contact des utilisateurs, ont déjà leurs outils. Il peut être intéressant de voir comment les connecter à celui du repository. N’hésite donc pas à tester les outils déjà en place et, si aucun n’est pertinent, à démarrer un benchmark sur la base des besoins et des ambitions que vous aurez identifiés avec l’équipe REPO.
Pour monter un repository d’insights, il y a plusieurs grands classiques : Airtable, Google Spreadsheet, Notion, Product Board, Dovetail… Chez Thiga, mais aussi chez LeBonCoin, Disneyland Paris ou Groupe SeLoger, notre préférence va vers Airtable pour sa modularité (facilité d’ajout de colonnes, de filtres, de tags…), sa gestion des accès (éditeur, lecteur…) et son rendu visuel. Si tu hésites, teste-en un ou deux avant de faire un choix.
Quel que soit ton choix final, une phase de formation et d’appropriation sera à prévoir à différents niveaux : pour les futurs contributeurs et pour les lecteurs.
Autre critère à prendre en compte : la gestion et le stockage des données. Même anonymisées, les informations renseignées dans un repository sont sensibles. Si tu choisis un nouvel outil, renseigne-toi auprès des services compétents (legal, IT…).
Structurer ton repository de recherche
Quelle est l’origine du repository de recherche ?
Parler de repository revient très vite à s’intéresser à l’Atomic Research. Toutefois, avant se mettre à courir, assurons-nous de bien savoir marcher (et si possible, pas sûr la tête 😉) !
Étant donné la complexité du sujet et de sa mise en œuvre, dans un premier temps, nous te recommanderons de construire une liste exhaustive des études menées.
Ce listing aura le mérite de centraliser toutes les restitutions, tagguées par sujet, et de donner une première visibilité sur le travail de recherche réalisé. Une fois que l’équipe aura acquis de la maturité et que l’intérêt des parties prenantes et des sponsors sera suscité, vous pourrez vous lancer dans l’aventure de l’Atomic Research.
Afin d’avoir une vision à plus long terme et même s’il est possible de commencer à monter son repository sans forcément adopter cette démarche, il est important d’en connaître les bases.
Suivant la tendance de l’Atomic Design (Pourquoi créer un Design System ? ; Comment initier un Design System lorsqu’on dispose de peu de ressources ?), et théorisée par Daniel Pidcock, l’approche d’Atomic Research consiste à organiser et présenter la connaissance de ses utilisateurs en découpant chaque feedback selon :
- l’expérience réalisée ou experiment - c’est-à-dire d’où vient la connaissance, par quelle méthode (tests d’utilisabilité, interviews…) nous vient-elle.
- les faits observés ou facts - le quoi, l’information directe (verbatim utilisateur, chiffre brut…).
- les insights - le pourquoi, l’explication contextualisée du fait. À noter qu’un insight peut répondre à plusieurs facts. Il peut s’agir d’un problème comme d’un constat positif.
- les recommandations - le comment répondre aux insights obtenus.
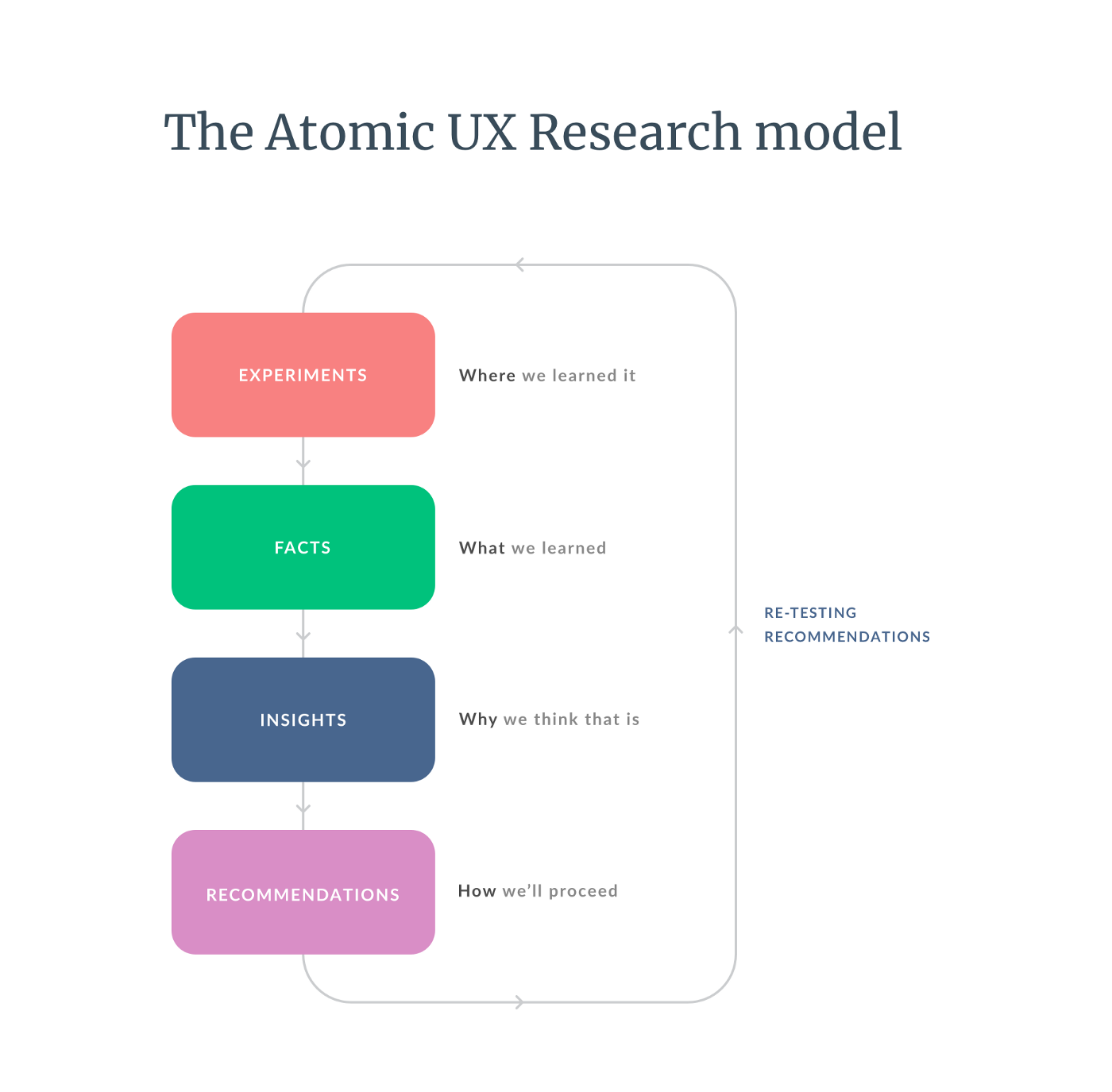
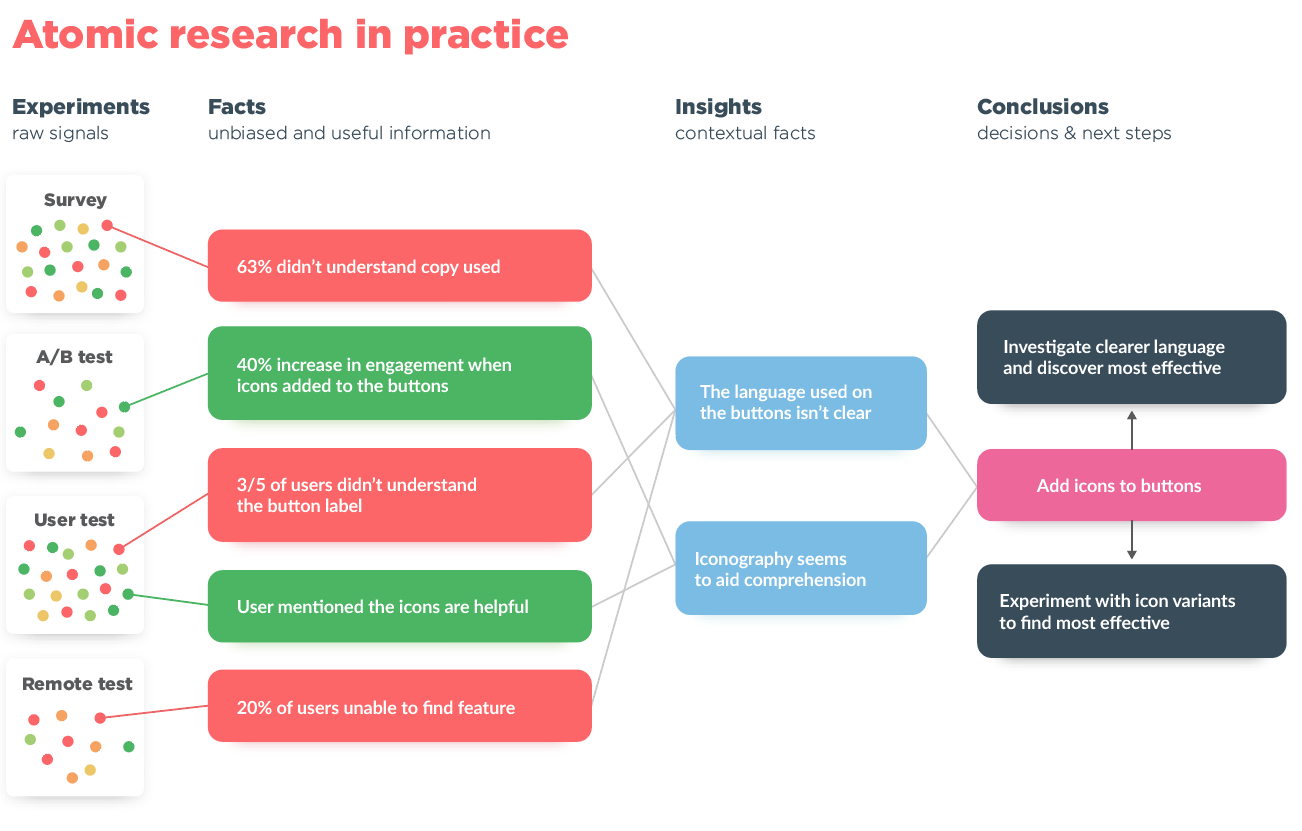
L’Atomic Research expliqué par Pidcock lui-même.
Pidcock a développé l’approche d’Atomic Research pour fonder ses décisions sur des preuves tangibles et sourcées. Ces preuves vont donc servir à diffuser la connaissance utilisateur obtenue et sensibiliser les équipes internes pour en faire des choix stratégiques, business et d’innovation. L’idée est de rompre avec une vision linéaire de la recherche (étude après étude) pour adopter une approche plus transverse en catégorisant et en centralisant les informations.
Au coeur de cette approche, tu l’auras compris, on retrouve notre base de connaissances sur les utilisateurs : le repository de recherche. Dans ce dernier, tu pourras agréger les feedbacks utilisateurs de tous les collaborateurs en contact avec les utilisateurs (Designers, service client, Commerciaux, etc.) et les repartager plus facilement au reste de ton organisation.
Appliquer la démarche d’Atomic Research est exigeant. Avant de commencer, tu dois définir le niveau de granularité du repository en fonction de deux critères :
- Les ressources allouées,
- La maturité de ton organisation.
🌍 Au fait, dans quelle langue rédiger et alimenter son repository ?
Pour les équipes qui mènent des études à l’international, la question est de taille. Deux critères rentrent en ligne de compte :
• la langue parlée par les utilisateurs du Produit
• … et celle des utilisateurs du repository et des restitutions !
Si la recherche est conduite en anglais et que l’équipe interne est anglophone, la question ne se pose pas ! On garde les faits, les insights et les restitutions dans cette langue. Dans le cas où les utilisateurs parlent des langues différentes, nous te recommanderons de conserver les faits dans la langue d’origine (et éventuellement de les faire traduire) mais de rédiger tout le reste en anglais. Enfin, même si tu es dans une entreprise avec des interlocuteurs uniquement francophones, pense à la scalabilité du repository : il est possible de laisser le contenu en français et d’avoir des en-têtes du tableau en anglais.
Adapter l’ambition de son repository en fonction de la maturité de l’organisation
Évaluer la maturité en recherche
Pour estimer la sensibilité et le niveau en recherche de ton organisation, tu peux utiliser la matrice de maturité des organisations en matière de recherche développée par Chris Avore :
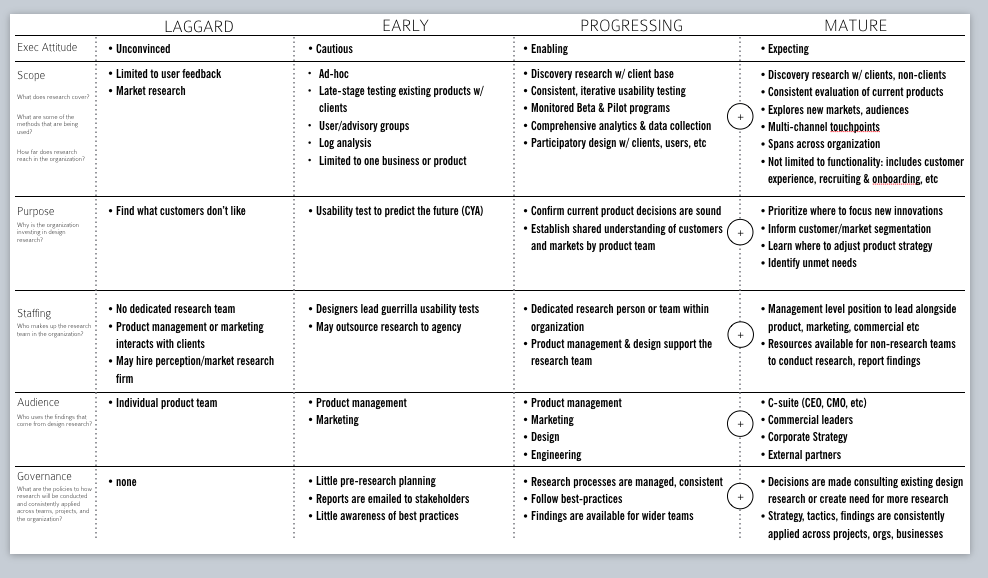
L’objectif est d’identifier :
- L’intérêt que porte les managers à l'égard de la recherche utilisateurs ;
- La portée de ta recherche (se fait-elle en continu ? Se limite-t-elle à de l’existant ou s’intéresse-t-elle a des sujets plus exploratoires ?)
- Comment la recherche est utilisée dans le processus de conception
- La ou les équipes dédiées à la recherche
- En interne, qui tient compte des enseignements de la recherche.
Sois réaliste : si tu constates que ton organisation se situe au niveau “laggard”, la priorité est de commencer à identifier des sujets d’étude puis à en lancer… avant de s’attaquer à un repository façon Atomic Research.
Déterminer les étapes de construction de son repository
Toutefois, si ton organisation se situe aux niveaux “early”, “progressing” ou “mature”, plusieurs étapes se profilent à l’horizon pour monter ton repository de recherche. Nous les avons référencées dans ce tableau, inspiré du travail de Nathan Curtis sur les degrés de maturités des design systems :
| STADES DE MATURITÉ D’UN REPOSITORY DE RECHERCHE |
||||
| Basique | Avancé | Expert | ||
| Éléments tangibles | Composés de | Les études utilisateurs d’une squad ou d’une tribe (comme chez LeBonCoin) catégorisées en :
|
Toutes les études utilisateurs catégorisées (comme chez Alma) en :
|
Toutes les études catégorisées + les insights et recommandations de tous les services internes (retours utilisateurs sollicités ou non) |
| Présentés sous forme de | Document (à l’état de POC) accessible uniquement à l’équipe REPO | Document partagé au sein de l’équipe Produit | Fichier collaboratif et partagé à l’organisation, avec récupération des insights automatique ou via un canal dédié. | |
| Éléments intangibles | Faits par |
|
|
|
| Pour servir | Les designers et le Produit | Toutes les parties prenantes (produit, design, tech, marketing…) | Toutes les parties prenantes (produit, design, tech, marketing…) | |
Bien sûr, ce tableau n’est pas à prendre au pied de la lettre : il donne des repères mais n’est pas une roadmap à suivre aveuglément.
En revanche, nous t’encourageons vivement à poser des jalons pour la construction de ton repository, et à le rendre visible des parties prenantes. Pour cela, aide-toi des tâches à réaliser planifiées dans ton kanban.
La taxonomie, ou la science de classifier les faits
Une fois les faits référencés, une étape essentielle t’attend : celle de la classification à l’aide de tags. Dans une approche atomic, les tags sont l’équivalent d’un organisme. Ils ont pour objectif de faciliter la recherche et la compréhension des faits — en ce sens, ils doivent s’appliquer à l’ensemble des études présentes dans le repository.
Pour dresser une liste de tags, pas de vérité générale, mais beaucoup (beaucoup) de test and learn à prévoir :
- Chaque organisation a sa propre liste de tags
- Plusieurs typologie de tags (orientés produit, utilisateurs…) peuvent être utilisés pour un même fait.
- S’il y a plusieurs typologies, chacune doit contenir plusieurs tags.
Voici des exemples de typologies de tags possibles (liste non exhaustive) :
| Typologie de tags | Exemples |
| Tags reprenant des thématiques produit | Fraude, facilité de paiement… |
| Tags révélant l’expertise design, produit ou tech impactée | UX writing, bug, UI… (une démarche adoptée, entre autres, chez Leetchi) |
| Tags témoignant de l’appréciation et des attentes des utilisateur·rices | Irritant, souhait, élément apprécié, bug… (comme chez LeBonCoin ou Alma) |
| ... |
Avec les tags, le plus dur c’est de se lancer ! Et devine quoi ? Cela se fait en équipe et avec les parties prenantes, en atelier. Voici quelques exemples de questions à vous poser :
- Quel est le parcours du produit concerné par ce fait ? Quelles fonctionnalités ?
- Quels sont les éléments de langage récurrents ?
- S’agit-il d’une proposition d’amélioration ? D’un irritant ? D’un élément perçu comme étant apprécié ?
Commencez petit, avec une liste restreinte de tags ; vous aurez tout le loisir de l’enrichir et le modifier par la suite si besoin. À l’usage, tu pourras uniformiser les tags récoltés lors de tes sessions de recherche afin d’en tirer le plein potentiel !
Maintenant que nous avons vu ce qui composait, en théorie, un repository de recherche, nous allons t’en présenter deux exemples de formats utilisés chez LeBonCoin et chez Alma. Ces formats reprennent les grands attendus de la démarche : l’objectif est de venir piocher dans les deux exemples pour construire le format le plus adapté à ta structure.
Quelques idées de structures pour ton repository
Le repository de recherche de LeBonCoin
Voici un exemple concret du repository réalisé sur Airtable, onglet après onglet :
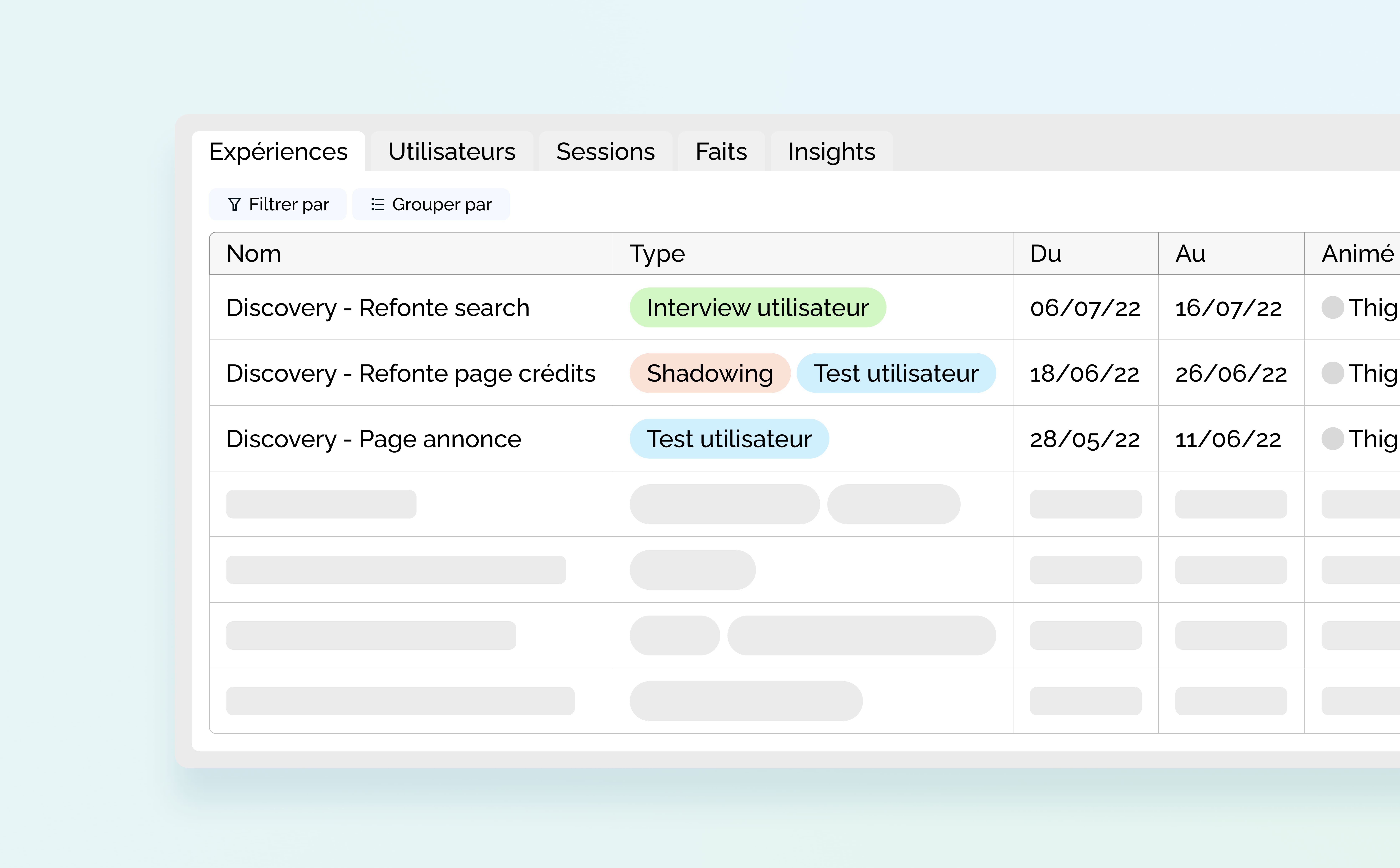
L’onglet “Expériences” regroupe les thématiques de Discovery sur lesquelles les Designers travaillent. On y retrouve :
- Le nom de l’initiative
- Le type d’expérience (c’est-à-dire l’experiment, la méthodologie de recherche)
- La date de début et de fin de l’étude
- La ou les fonctionnalités, parcours ou pages concernés par l’étude
- Le nom de la personne qui a animé l’étude
- La redirection vers les sessions associées filtrées
- Le nombre de sessions réalisées
- Le nombre de sessions à réaliser
L’onglet “Utilisateurs” permet de garder une trace des utilisateurs contactés. Il comprend leurs coordonnées, la date du dernier échange et les études auxquelles l’utilisateur a participé. Chaque utilisateur est classé par persona.
Attention toutefois à la compliance RGPD : les données personnelles doivent rester confidentielles et être accessibles uniquement par les personnes en charge de l’animation de la communauté et du recrutement. Rapproche-toi des experts légaux de ton entreprise pour connaître les bonnes pratiques (anonymisation des utilisateurs, suppression des données…).
L’onglet “Sessions” regroupe chaque session individuelle d’une expérience, avec :
- Numéro du participant (P1, P2, P3, etc.)
- L’experimentation
- La date
- Le persona associé
- La localisation de l’utilisateur
- Le nom de la personne qui a animé la session
- Le lien vers l’enregistrement
- Les faits rattachés à cette session.
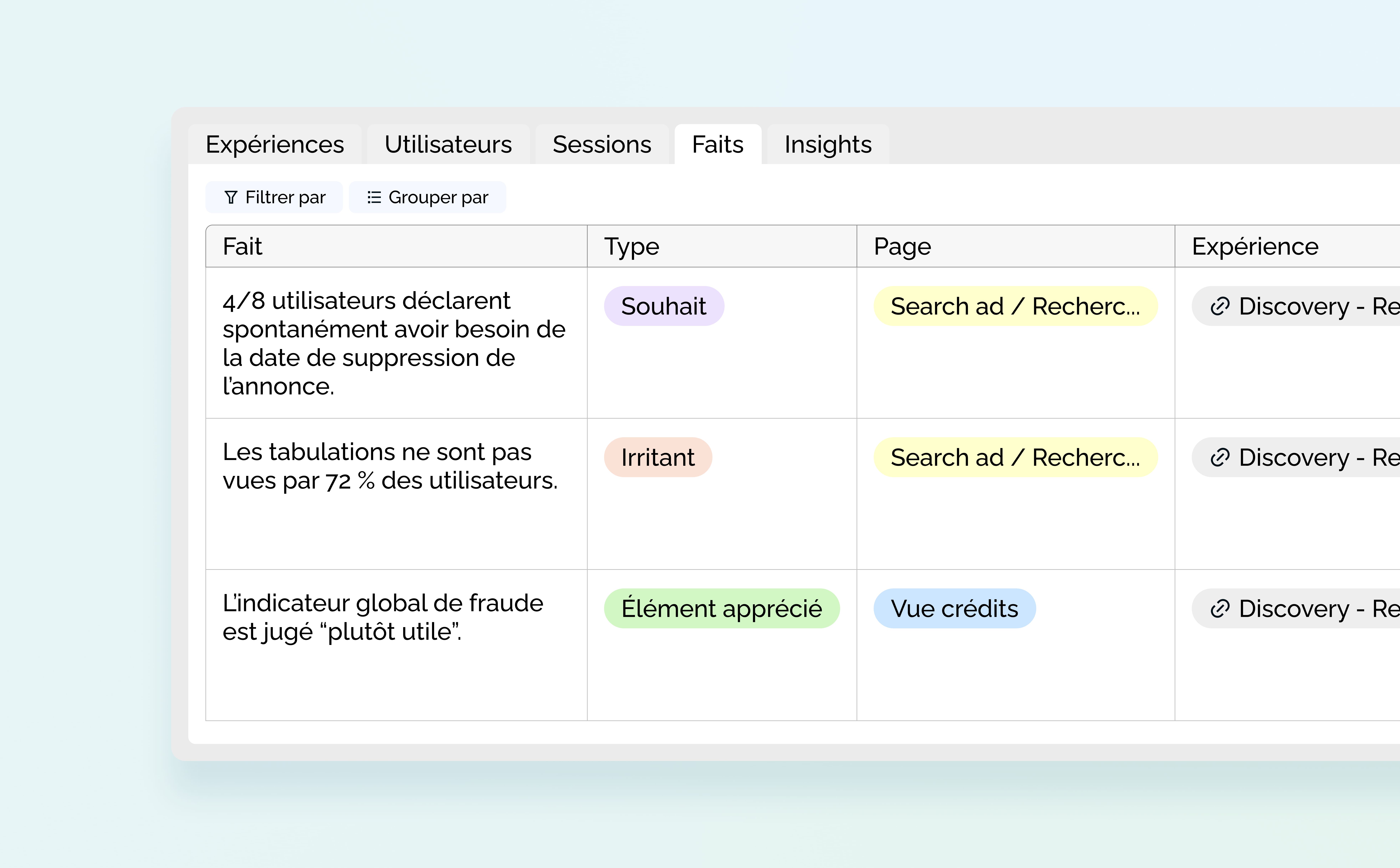
L’onglet “Faits” intègre les informations atomiques les plus fines. À chaque fait est rattaché un tag unique, qui peut être :
- Un irritant
- Un souhait
- Un élément apprécié
- Un bug
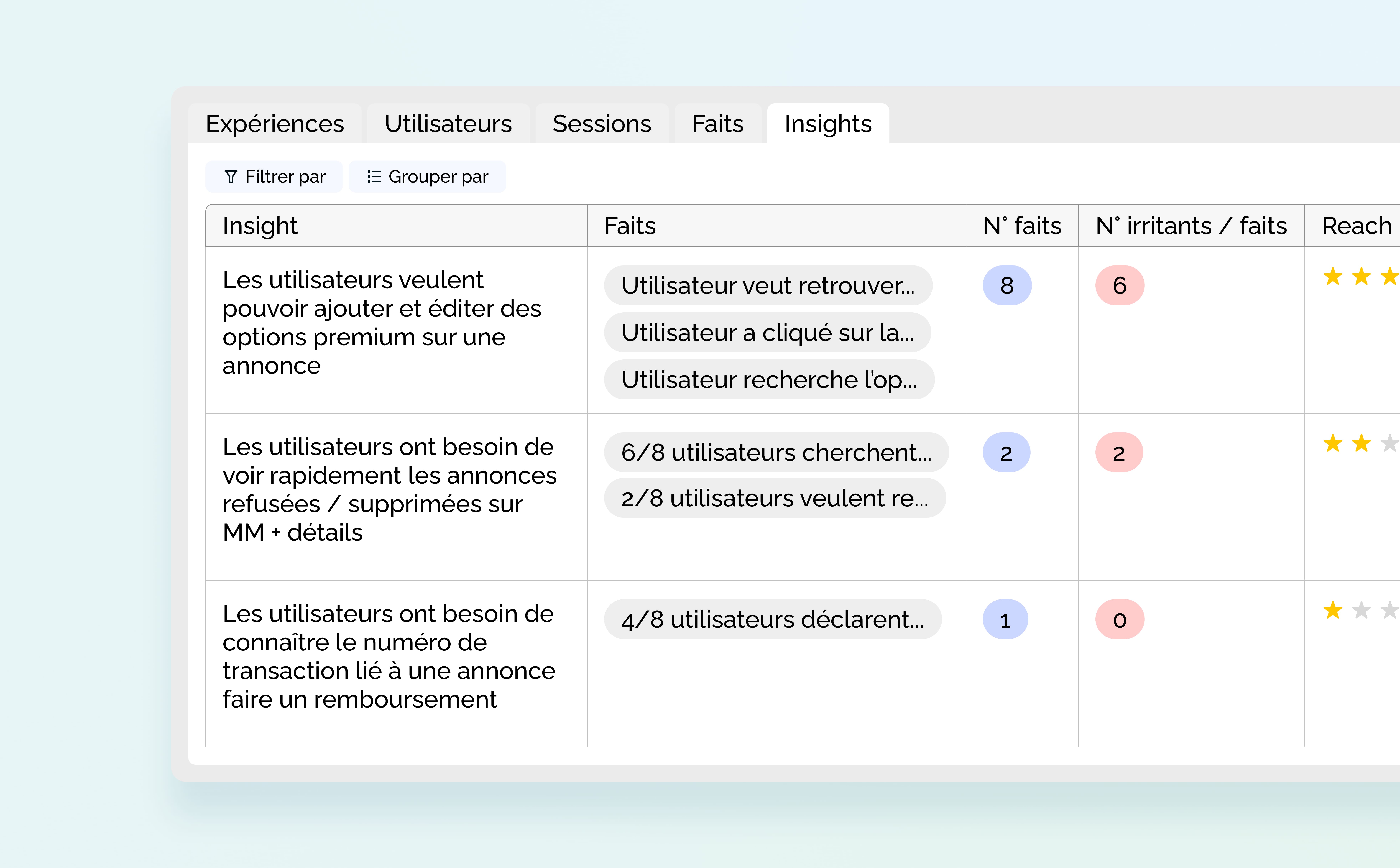
Enfin, nous arrivons à l’onglet “Insights”, le regroupement de faits concordants avec :
- L’insight
- Le regroupement des faits rattachés au même insight
- Le nombre total de faits associés à l’insight (3, 4…)
- Parmi ces faits, combien sont des irritants
Puis chaque insight est priorisé selon la méthode (P)RIC :
- R pour Reach (portée), soit le nombre d’utilisateurs concerné par cet insight
- I pour Impact, à savoir sa criticité
- C pour Confidence, c’est-à-dire la confiance qu’on accorde à cet insight. Pour définir et améliorer la “Confidence”, on te recommande le “Confidence Meter” proposé par Itamar Gilad.
Chaque critère (reach, impact et confidence) est noté de 1 à 5 et correspond à une colonne du repository. Grâce à un savant calcul (R x I x C), tu obtiens le score de priorisation de ton insight.
Nous te recommandons de prioriser avec ton équipe (ou du moins avec ton ou ta Product Manager) et de définir au préalable avec eux ce que représente un 1, un 2, un 3, etc.
Dernier conseil sur cette priorisation, n’hésite pas à ajouter pour chaque critère une colonne pour justifier ta notation. Par exemple : tu as mis 3 en reach car l’insight s’appuie sur un test d’utilisabilité réalisé sur 5 utilisateurs. Dans ce cas, il mériterait d’être validé par du quantitatif.
🧐 Comment passer du fait à l’insight ?
Transformer un ou plusieurs faits en insight exige un peu de pratique afin d’éviter quelques pièges : introduire des biais, proposer une solution, blâmer les utilisateurs… À tel point que le sujet mériterait un article ! Ça tombe bien, celui-ci te donnera des clés pour rédiger une trame commune : Key insight - très utile si vous êtes plusieurs à faire cet exercice !
Le repository d’insights d’Alma
Autre contexte, autre exemple. Chez Alma, le travail de recherche s’organise autour d’un “Brief initiative”. Une initiative est un sujet de Discovery.
Un “Brief initiative” peut regrouper plusieurs études, toutes catégorisées de la façon suivante :
- Des tags, qui correspondent à des thèmes produits (B2B, Merchant, Sellers, Mobile App…)
- Le lien vers l’étude
- Le statut (on going, on hold…)
- La méthodologie (Market Research, User Interview, Survey — avec une deuxième couche de tags pour “Quanti”, “Quali”)
- L’initiative de recherche (appelée “brief initiative”) à laquelle l’étude est liée
- Le pays
- La période
- Les personnes engagées.
Au sein des études, le contexte et les informations récoltées lors des sessions sont organisées de la façon suivante :
- Les objectifs
- Le protocole
- La cible utilisateur
- Les hypothèses que l’on souhaite vérifier en indiquant :
- Le moment du parcours utilisateur (ex. pré-achat, post-achat…)
- Le niveau de confiance
- La validation ou invalidation de l’hypothèse.
Enfin, les insights sont classés en quatre catégories :
- Les irritants
- Les motivations à utiliser le produit
- Les fonctionnalités les plus plébiscitées
- Les idées (ou suggestions) de fonctionnalités.
.jpg?width=7852&name=feedbacks%20(2).jpg)
En complément de ces tableaux, l’équipe d’Alma a ajouté une section avec quatre insights-clés dans chaque restitution. L’objectif est de donner plus d’impact à la Discovery, en facilitant le partage et la mémorisation de ces enseignements pour un public varié (Country Managers, Service Client, Marketing…).
Pour exceller en Product Discovery : Inscris-toi à notre formation Discovery Discipline
Que retenir ?
Au même titre qu’un design system, gardons en tête que le repository de recherche est un produit à part entière, que tu vas faire évoluer en équipe. Sa modularité et sa scalabilité sont donc deux points cruciaux.
La prise en main de l’outil nécessitera du temps et il faudra compter plusieurs itérations pour le consolider. Après l'avoir mis à l'épreuve, vient le moment de maintenir ce repository et d'utiliser efficacement son contenu, notamment en pondérant les insights.
Merci à Louise, Xavier, Anh-Minh et Mathias pour leurs retours d’expérience.
Ils ont écrit cet article avec ❤️ : Éva Zuliani et Victor Pineau




